数据存储技术复习(四) 数据处理与存储服务的演进与融合
在数据存储技术的学习版图中,数据处理与存储服务是不可或缺的核心组成部分。随着数据规模的爆炸式增长和应用需求的日益复杂,两者之间的关系已从简单的“存”与“取”,演变为深度协同、互为支撑的有机整体。本部分将探讨数据处理范式与存储服务的发展脉络及其在现代架构中的关键角色。
一、 数据处理范式的演进:从批处理到实时流
数据处理技术大致经历了三个主要阶段:
- 批处理(Batch Processing):以Hadoop MapReduce为代表,其核心理念是“移动计算而非数据”。数据首先被持久化存储在HDFS等分布式文件系统中,然后计算框架调度任务到数据所在节点进行处理。这种方式吞吐量高,适合海量历史数据的离线分析,但延迟通常较高(小时级或天级)。
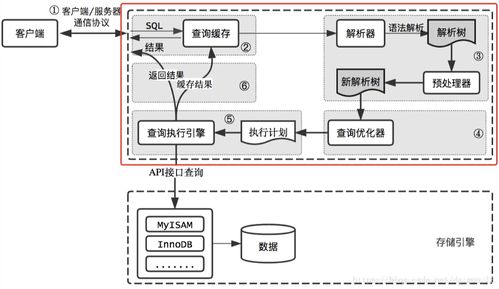
- 交互式处理(Interactive Processing):为了降低分析延迟,出现了如Apache Spark、Impala、Presto等内存计算或MPP(大规模并行处理)引擎。它们通过内存缓存、向量化执行、优化查询计划等手段,将查询响应时间缩短到秒级甚至亚秒级,支持即席查询(Ad-hoc Query)。这对底层存储的随机读取性能和元数据管理提出了更高要求。
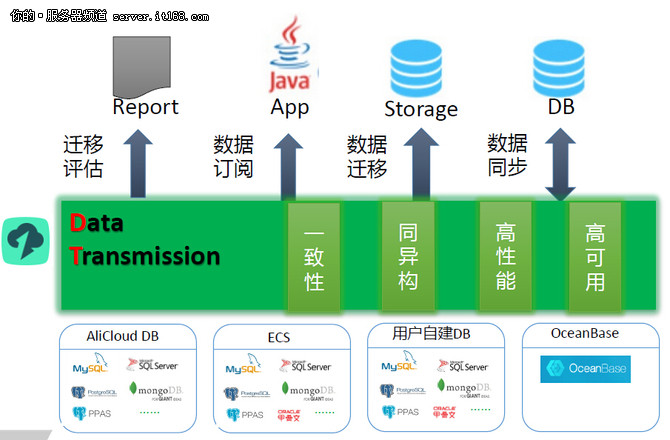
- 流处理(Stream Processing):随着物联网、实时监控等场景的兴起,Apache Flink、Apache Storm、Spark Streaming等流处理框架应运而生。它们对无界数据流进行连续、低延迟(毫秒到秒级)的处理。这要求存储系统不仅能提供高吞吐的写入以接收数据流(如Kafka作为流存储层),还能支持状态的可靠持久化存储,并与批处理存储(如数据湖)实现无缝集成,形成 Lambda架构 或更先进的 Kappa架构。
二、 存储服务的分层与抽象
现代数据存储服务已高度分层和专业化,旨在为不同的数据处理需求提供最合适的接口与性能。
- 对象存储(Object Storage):以AWS S3、阿里云OSS为代表,已成为数据湖(Data Lake)的事实标准底座。它提供近乎无限的扩展性、高耐久性和低成本,通过RESTful API进行访问。其键值对模型和“一次写入、多次读取”的特性,非常适合存储原始、半结构化和非结构化数据,供后续的批处理或交互式分析使用。
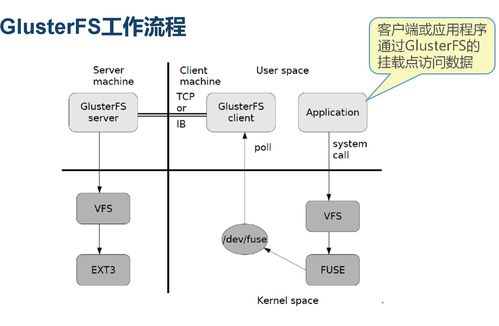
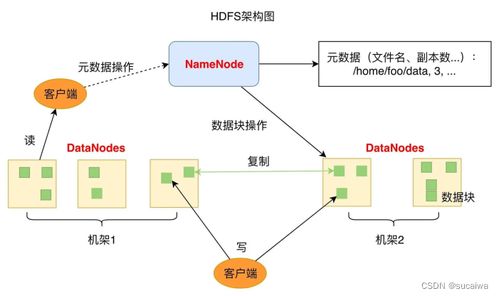
- 分布式文件系统(Distributed File System):如HDFS、CephFS,提供类似于传统POSIX的文件系统接口,更适合需要文件语义(如顺序读写、目录树)的应用程序。HDFS长期以来是Hadoop生态的存储基石,但其扩展性和小文件处理能力面临挑战。
- NoSQL数据库(键值、宽列、文档、图):为特定的数据模型和访问模式优化,提供低延迟的随机读写能力。例如,Cassandra、HBase适合时间序列或宽表查询;MongoDB适合灵活的文档模型;Redis提供极致性能的内存键值存储。它们通常作为在线业务系统的后端存储或实时计算的状态存储。
- 云原生数据库与数据仓库:如Snowflake、BigQuery、Redshift、Azure Synapse Analytics等,将存储与计算彻底解耦。计算资源可以独立弹性伸缩,共享同一份持久化的数据。它们通常内置了强大的列式存储、自动优化和SQL查询引擎,直接提供高性能的分析服务,极大地简化了数据架构。
三、 数据处理与存储的融合趋势
当前最显著的趋势是 “存算分离” 与 “湖仓一体”。
- 存算分离:将存储资源与计算资源独立管理、按需伸缩。这不仅带来了极致的弹性和成本效益(仅为使用的资源付费),还使得同一份数据可以被多个异构的计算引擎(如Spark、Flink、Presto)同时访问和分析,避免了数据孤岛和重复拷贝。对象存储是存算分离架构中理想的持久化层。
- 湖仓一体(Lakehouse):旨在融合数据湖的灵活性与数据仓库的管理性能。以Databricks Delta Lake、Apache Iceberg、Apache Hudi为代表的开源表格式(Table Format)是关键。它们在对象存储之上,通过事务日志、ACID事务、模式演化、高效元数据管理等机制,构建出兼具数据湖低成本存储和数仓高性能SQL分析、数据治理能力的统一数据平台。数据处理作业可以直接读写这些“表”,享受事务保证和性能优化。
四、 与展望
数据处理与存储服务的发展,始终围绕着 效率、成本、易用性、实时性 这四大核心目标螺旋上升。未来的方向将更加聚焦于:
- 智能化:存储系统将内置更多智能,如自动分层(热、温、冷数据)、数据生命周期管理、基于访问模式的自动索引与优化。
- 一体化与标准化:“湖仓一体”架构将继续成熟,Table Format有望成为跨引擎数据访问的通用标准层,进一步模糊数据处理与存储的边界。
- 实时化与流批统一:存储系统将提供更强大的流式数据接入和实时服务能力,支持流批一体处理范式,满足愈发迫切的实时决策需求。
理解数据处理需求如何驱动存储技术的演进,以及不同存储服务如何适配特定的计算范式,是设计和构建高效、稳健、可扩展数据系统的关键。数据处理与存储服务的深度融合,正推动我们进入一个数据价值被更便捷、更实时挖掘的新时代。
如若转载,请注明出处:http://www.lookmq.com/product/66.html
更新时间:2026-06-19 15:32:36