大模型与AIGC浪潮下,数据中心存储的演进与挑战

以大型语言模型(LLM)和生成式人工智能(AIGC)为代表的人工智能技术正以前所未有的速度和规模重塑着数字世界。这场技术革命不仅催生了ChatGPT、Midjourney等明星应用,更在底层基础设施领域,尤其是数据中心的数据处理和存储服务方面,引发了深刻而持续的变革。大模型与AIGC的“火热”状态,正从数据规模、处理范式、性能需求和服务模式等多个维度,强力驱动着数据中心存储技术的新趋势。
一、 数据量的爆炸式增长催生海量、高性能存储需求
大模型与AIGC的训练和应用,其基石是海量的数据。无论是用于模型训练的文本、代码、图像、视频等多模态数据,还是模型推理时产生的交互数据,其规模都达到了PB乃至EB级别。这直接导致:
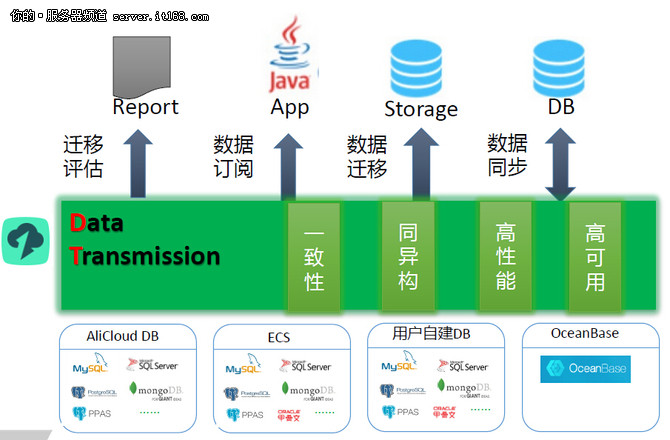
- 存储容量需求激增:数据中心需要部署能够线性扩展、管理海量非结构化数据的存储系统,对象存储因其无限扩展性和高性价比,成为存储原始训练数据和生成内容(如AI生成的图片、视频)的主流选择。
- 高性能数据访问成为刚需:模型训练是一个密集型计算过程,需要存储系统能够以极高的吞吐量(带宽)和IOPS(每秒读写次数)向GPU计算集群“喂数据”,以避免计算资源闲置。全闪存阵列(AFA)和基于NVMe协议的高性能分布式存储因此成为训练平台的关键组成部分。
二、 数据处理范式的转变:从“存算分离”到“存算协同”与“近计算存储”
传统数据中心常采用“存算分离”架构以提升灵活性和资源利用率。大模型训练对数据访问延迟极其敏感,频繁的网络传输可能成为瓶颈。因此,新趋势显现:
- 存算一体化的加速:在AI计算节点(服务器)内部或紧邻处部署高性能本地NVMe SSD,用于存放热数据集或作为高速缓存,实现数据在计算单元旁的极速访问,形成“存算协同”的紧耦合架构。
- 分层存储与智能数据调度:数据中心存储系统正变得更智能化,能够根据数据的热度(访问频率)自动在高速存储层(如SSD)、容量层(如HDD对象存储)乃至冷存储层之间迁移数据。热数据近计算,冷数据远归档,从而实现成本与性能的最优平衡。
三、 对数据服务模式的深远影响:从资源供给到价值赋能
大模型/AIGC工作负载的复杂性,使得单纯提供块、文件、对象接口的标准化存储资源已不足以满足需求。数据处理和存储服务正在向更深层次演进:
- 一体化AI数据平台兴起:服务商开始提供整合了数据采集、预处理、标注、存储、版本管理以及高性能供给的端到端数据平台。存储不再是一个孤立的资源池,而是AI流水线中智能、主动的一环。例如,专为AI设计的存储系统能理解训练任务的数据访问模式,进行预取和优化。
- 对数据质量、治理与安全的要求空前提高:大模型的输出质量严重依赖于输入数据的质量。因此,存储服务需要与数据清洗、去重、标注、血缘追踪等治理工具深度集成,确保数据的合规性、一致性和可追溯性。AIGC生成的敏感内容、训练所用的版权数据等,也对存储的安全性、加密和访问控制提出了更高要求。
- 绿色与可持续性成为重要考量:庞大的存储集群意味着巨大的能耗。在追求高性能的采用高密度硬件、更高效的编码技术(如纠删码)、以及利用冷存储归档不常用数据以降低总体能耗,已成为数据中心存储设计和运营的关键趋势。
四、 未来展望:技术融合与生态重构
大模型与AIGC的影响将持续深化:
- 存储介质创新:SCM(存储级内存)等新介质可能在缓存和内存层级中扮演更重要的角色,进一步模糊内存与存储的界限。
- 软件定义与协议演进:存储软件将更加AI原生,能够动态适配AI工作负载。NVMe-of(NVMe over Fabrics)协议将进一步普及,实现数据中心级的高性能存储网络。
- 云边协同存储:随着AIGC应用向边缘扩展(如手机、IoT设备),如何高效管理从边缘到中心的数据流水线,将成为存储架构的新课题。
结论
总而言之,火热的大模型与AIGC绝非仅仅是上层应用的狂欢,它们正作为最强劲的驱动引擎,倒逼数据中心存储基础设施进行一场从量变到质变的升级。趋势的核心是从被动、通用的“数据仓库”,转向主动、智能、高性能的“数据引擎”。未来的数据处理和存储服务,将更加紧密地与计算融合,更智能地管理数据全生命周期,并以平台化的方式为AI的开发和部署提供核心赋能。对于数据中心运营商、存储厂商及云服务提供商而言,拥抱这些趋势,不仅是应对挑战的必需,更是赢得下一个时代竞争力的关键。
如若转载,请注明出处:http://www.lookmq.com/product/62.html
更新时间:2026-06-19 09:44:08