极简存储史 从单机、集中式、分布式到云原生数据处理与存储服务
数据存储技术的发展,是信息时代演进的核心脉络之一。它从最初简单的本地保存,逐步演变为支撑全球数字化浪潮的复杂服务。这条演进路径可以清晰地划分为四个主要阶段:单机存储、集中式存储、分布式存储,以及如今的云原生存储与数据处理服务。
1. 单机存储:数据与计算的“一体时代”
这是存储史的起点。在早期计算机系统中,存储与计算紧密耦合。数据直接存放在与中央处理器(CPU)直接相连的存储介质上,如打孔卡片、磁带、早期的硬盘。其特点是容量小、速度慢,且数据无法被其他系统直接访问。数据处理是纯粹的本地操作,数据即“文件”,存储即“设备”。这一阶段的核心是解决“有地方存”的问题。
2. 集中式存储:数据资源的“池化时代”
随着网络(尤其是局域网)的出现和业务数据量的增长,数据共享的需求催生了集中式存储。以存储区域网络(SAN)和网络附加存储(NAS)为代表,存储设备从服务器中剥离出来,成为独立的、通过网络为多台服务器提供块级或文件级存储服务的专用设备。数据实现了初步的集中管理和共享,提升了可靠性和管理效率。大型磁盘阵列(RAID)技术是这一时期的标志,它通过冗余保障了数据安全。此时,存储开始被视为一种独立的“资源”。
3. 分布式存储:面向海量数据的“扩展时代”
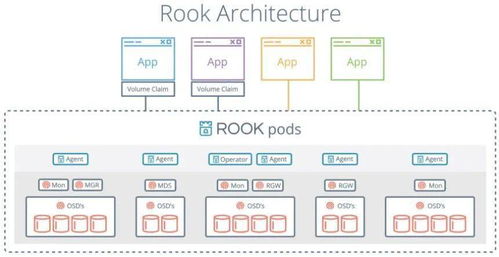
互联网和Web 2.0的爆发带来了数据量的指数级增长,集中式存储在容量和性能的扩展上遇到了瓶颈。分布式存储应运而生。其核心思想是将数据分散存储到大量廉价的、标准的服务器硬盘上,并通过软件层面的冗余(如多副本、纠删码)和一致性协议来保证数据的可靠性与可用性。谷歌的GFS、开源的HDFS、Ceph等都是典型代表。这一阶段,存储系统的设计目标转向了可线性扩展、高容错和低成本,以应对海量非结构化数据(图片、视频等)的挑战。数据处理也进入了以Hadoop MapReduce为代表的离线批处理时代。
4. 云原生存储与数据处理服务:智能与敏捷的“服务时代”
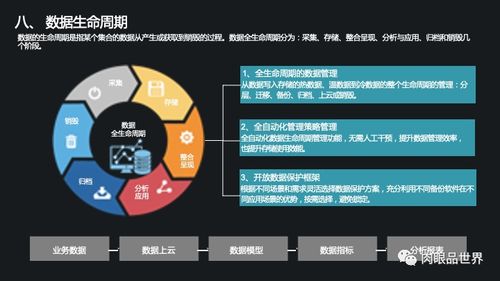
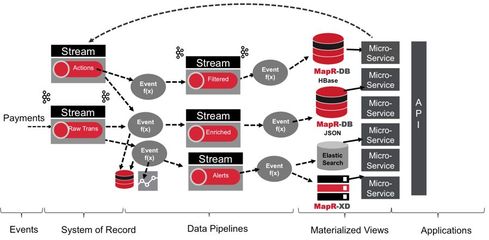
云计算成为主流范式后,存储进入了云原生时代。其核心特征不再是单纯的存储设备或软件,而是与计算深度整合、以API方式提供的“服务”。对象存储(如AWS S3)成为海量非结构化数据的标准归宿;云数据库(RDS、NoSQL服务)提供了完全托管的数据管理能力。更重要的是,存储与数据处理的界限变得模糊。以Snowflake、Databricks为代表的云原生数据平台,将存储、计算、缓存完全分离并独立弹性伸缩,用户无需关心底层基础设施,只需为实际消耗的资源付费。数据处理模式也演进为流批一体和实时分析。数据湖、数据湖仓一体等概念,强调以原始格式集中存储所有数据,并支持多样化的分析引擎按需访问。
演进脉络与未来展望
纵观这段历史,存储演进的驱动力始终是数据规模的增长、访问模式的变迁和对敏捷性与成本的不懈追求。其趋势清晰可见:
- 从紧耦合到解耦与分离:计算与存储分离,控制平面与数据平面分离。
- 从硬件定义到软件定义:智能与功能越来越多地由软件实现,硬件趋于标准化、通用化。
- 从资源到服务:用户体验从管理物理设备,转变为消费API接口和SLA(服务等级协议)。
- 从静态到智能:存储系统开始集成数据管理、分析、安全与合规等高级智能功能。
随着人工智能的普及,存储系统将需要更高效地支撑向量数据等新型负载,并与AI训练/推理流程深度集成。在边缘计算场景下,存储将再次呈现“分布式”与“轻量云原生”结合的新形态。不变的是,存储作为数据价值基石的角色将愈发重要,并持续向更智能、更无缝、更经济的服务化方向演进。
如若转载,请注明出处:http://www.lookmq.com/product/55.html
更新时间:2026-06-19 10:58:40