揭秘LinkedIn大数据后台的运作机制 从数据库到数据处理和存储服务
LinkedIn作为全球领先的职业社交平台,其大数据后台系统在支撑着数亿用户的日常互动和数据管理。该系统的核心依赖于高效的数据信架构、先进的数据处理技术以及可靠的存储服务。以下将详细解析LinkedIn大数据后台的运作流程。
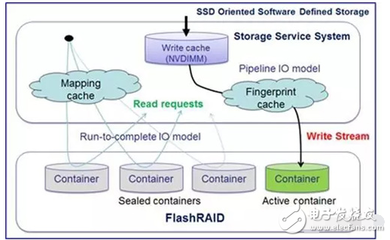
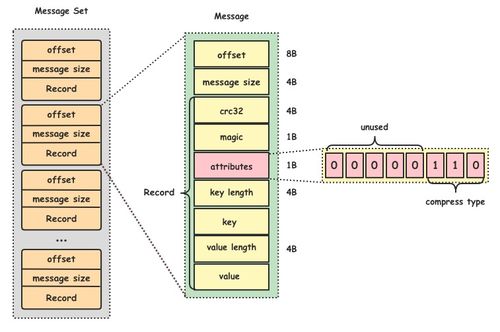
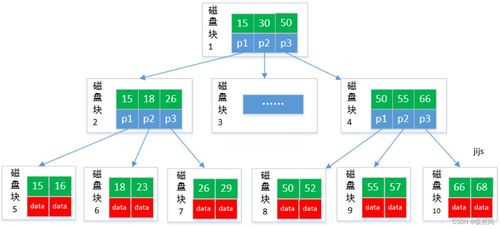
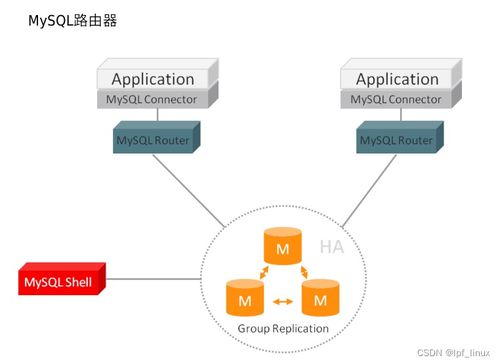
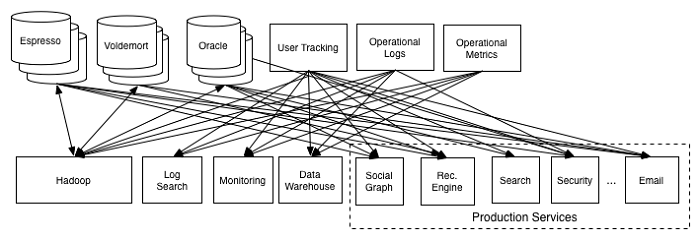
LinkedIn采用分布式数据信系统来管理海量数据。该平台早期使用关系型数据信,但随着数据量的激增,逐步迁移到NoSQL和NewSQL解决方案,如Apache Kafka用于实时数据流处理,以及Voldemort和Espresso等自研数据信系统。这些系统支持高可用性和水平扩展,确保用户资料、连接关系和活动日志等数据能够快速读写和查询。
数据处理是后台运作的关键环节。LinkedIn使用Apache Hadoop和Apache Spark等开源框架进行批处理和实时计算。例如,通过Spark Streaming处理用户行为数据,生成个性化推荐和洞察报告。数据管道还包括ETL(提取、转换、加载)过程,将原始数据转化为结构化格式,用于分析和机器学习模型训练,从而优化用户体验和业务决策。
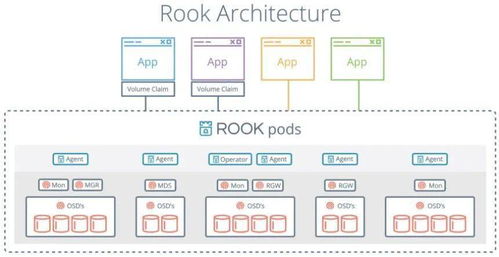
存储服务方面,LinkedIn结合了多种存储技术。对象存储用于处理非结构化数据,如用户上传的文档和图片,而分布式文件系统如HDFS则用于大数据集的长期存储。通过火龙果软件工程等专业服务,LinkedIn实现了数据处理和存储的自动化监控与优化,确保系统在高并发场景下的稳定性和性能。
LinkedIn大数据后台通过整合先进的数据库技术、高效的数据处理流程和可靠的存储服务,构建了一个可扩展、高可用的生态系统。这不仅提升了平台的响应速度,还为持续创新和数据驱动决策奠定了坚实基础。
如若转载,请注明出处:http://www.lookmq.com/product/6.html
更新时间:2026-06-19 13:30:45